Go database/sql vs jmoiron/sqlx reading benchmark
Publish date: 2019-09-05
Intro
While building most of projects or apps it is very common to read from a
database. In go standard way to do that is by using
database/sql standard library.
To illustrate how it can be done let's load from database a bunch of
Points which are slice of Points defined as follows
type Point struct {
X int
Y float64
}
type Points []Point
Next listening contains definition of function ReadPoints which for existing
*sql.DB database connection reads
Points. It tries to execute SQL query passed as string from function (not
listed) PointsQuery. Then slice for results is created and in for loop
there is reading row-per-row and writing points into points slice.
func ReadPoints(dbConn *sql.DB) Points {
rows, qErr := dbConn.Query(PointsQuery())
if qErr != nil {
fmt.Println("Couldn't execute the query")
}
defer rows.Close()
points := make(Points, 0, 10000)
var (
x int
y float64
)
for rows.Next() {
rows.Scan(&x, &y)
points = append(points, Point{x, y})
}
return points
}
This implementation of reading Points is independent of specific database. It
is based only on database/sql package and doesn't depends on specific database
driver.
There is nothing wrong with this approach but it could be a bit tedious in case when
you have to read dozens or even hundreds of queries from the database. In this
case one usually creates one file per reading containing definition of the type for
query result, definition for query and reading function. Is there any more compact
solution? It would be great if something similar to
json.Unmarshal, which can
use struct's tags to read and writes JSONs, exists. Fortunately there is
jmoiron/sqlx package.
jmoiron/sqlx package
Package sqlx is open-source and MIT-licensed go package created to extend
functionalities from standard database/sql package.
sqlx is a library which provides a set of extensions on go's standard
database/sqllibrary. The sqlx versions ofsql.DB,sql.TX,sql.Stmt, et al. all leave the underlying interfaces untouched, so that their interfaces are a superset on the standard ones. This makes it relatively painless to integrate existing codebases usingdatabase/sqlwith sqlx.
Regarding reading from database we are especially interested in
sqlx.Select
function. To perform reading Points using this function we have to add
tags
in Point (assuming query contains column names "pointX" and "pointY") structure
as follows
type Point struct {
X int `db:"pointX"`
Y float64 `db:"pointY"`
}
Now we can implement alternative (compact) version of function ReadPoints
using package sqlx. This version creates new slice of points, passes it into
sqlx.Select function together with the query to read points from database.
func ReadPointsSQLX(dbConn *sqlx.DB) Points {
points := make(Points, 0, 10000)
err := sqlx.Select(&points, PointsQuery())
if err != nil {
fmt.Println("Error while reading Points.")
}
return points
}
Obviously sqlx.Select uses reflection
to deal with its input data (passes as interface). Therefore my question is
How much do we pay for runtime overhead using package sqlx instead of
standard approach? I want to answer this question by performing series of
benchmarks.
Benchmark methodology
My first attempt to perform this benchmark was by using standard go test -bench
benchmark. It was somehow ok but it gave me only average time of reading. There
was also difference if I would benchmark standard approach first then sqlx or
vice versa.
We have to keep in mind that our benchmark depends on database and its current state. To perform faithful benchmark I've proposed the following algorithm:
- Choose first method (standard vs
sqlx) of reading at random (with equal distribution) - Perform first method reading
- Perform second method reading
- Save statistics
- Wait for few seconds
- Repeat from 1.
So this algorithm performs reading using both methods (sometimes in different order) in a chunk, then waits. In my opinion this approach assures that both single reading are performed on database with its similar state. In results I've also skipped first five measurements treating it as a warm-up.
This algorithm was applied for query which returns 1k, 10k, 100k, 1mil and
10mil Points, 95 times for each case. For further comparison this procedure
was also applied to extended Points with ten fields (4 x int, 3 x string,
3 x float64) instead of two.
In Appendix there is description of environment I've used to perform the following results.
Benchmark results
Raw benchmark results are composed of two files
BenchResults.txt
and
BenchResults_TenCols.txt
for two column case and ten column case respectively. Time in those files is
presented in nanoseconds. To reasonably compare overhead of sqlx reading
over standard one we should focus on percentage difference (Diff perc)
defined as
The following two tables presents average (from 95 measurements) reading time
for database/sql and sqlx package expressed in seconds and theirs percentage
difference.
Results for 2 columns
| #Rows | Avg sql time [s] | Avg sqlx time [s] | Diff perc |
|---|---|---|---|
| 1 000 | 0.0046 | 0.0049 | 6.80% |
| 10 000 | 0.0228 | 0.0237 | 3.89% |
| 100 000 | 0.1992 | 0.2021 | 1.42% |
| 1 000 000 | 1.5478 | 1.5529 | 0.33% |
| 10 000 000 | 25.7208 | 27.1226 | 5.17% |
Benchmark results for 2 columns
Results for 10 columns
| #Rows | Avg sql time [s] | Avg sqlx time [s] | Diff perc |
|---|---|---|---|
| 1 000 | 0.0096 | 0.0100 | 3.52% |
| 10 000 | 0.0557 | 0.0587 | 5.15% |
| 100 000 | 0.4968 | 0.5099 | 2.56% |
| 1 000 000 | 6.2670 | 6.4906 | 3.44% |
| 10 000 000 | 75.9548 | 79.2614 | 4.17% |
Benchmark results for 10 columns
Figures Figure 1 and Figure 2 displays distribution of percentage
difference for each number of rows with distinction whenever standard
database/sql reading was first or second in benchmark algorithm. As you can
see there is significant difference between case when standard reading was first
and the case where it was executed second. When standard reading was executed
first then usually sqlx reading was faster! It is caused probably by database
caching rather then unusual behavior of go code. Because of this in mentioned
benchmark algorithm order of execution was sampled with equal distribution to
got averaged unbiased results.
Another interesting thing is that with number of rows percentage difference goes closer to 0 and variance decreases.
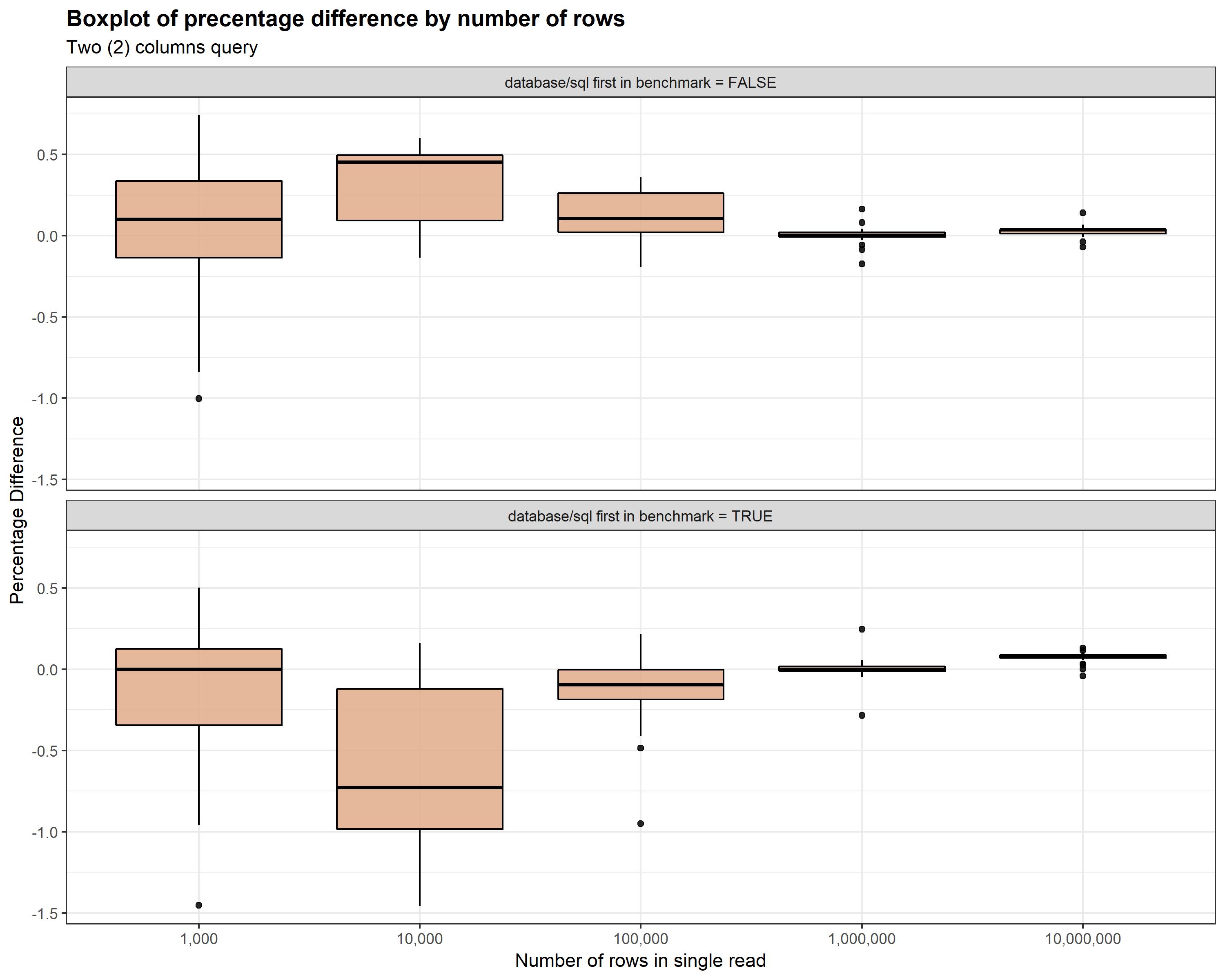
Figure 1: Boxplot of percentage difference in reading time by number of rows - case for two columns Points.
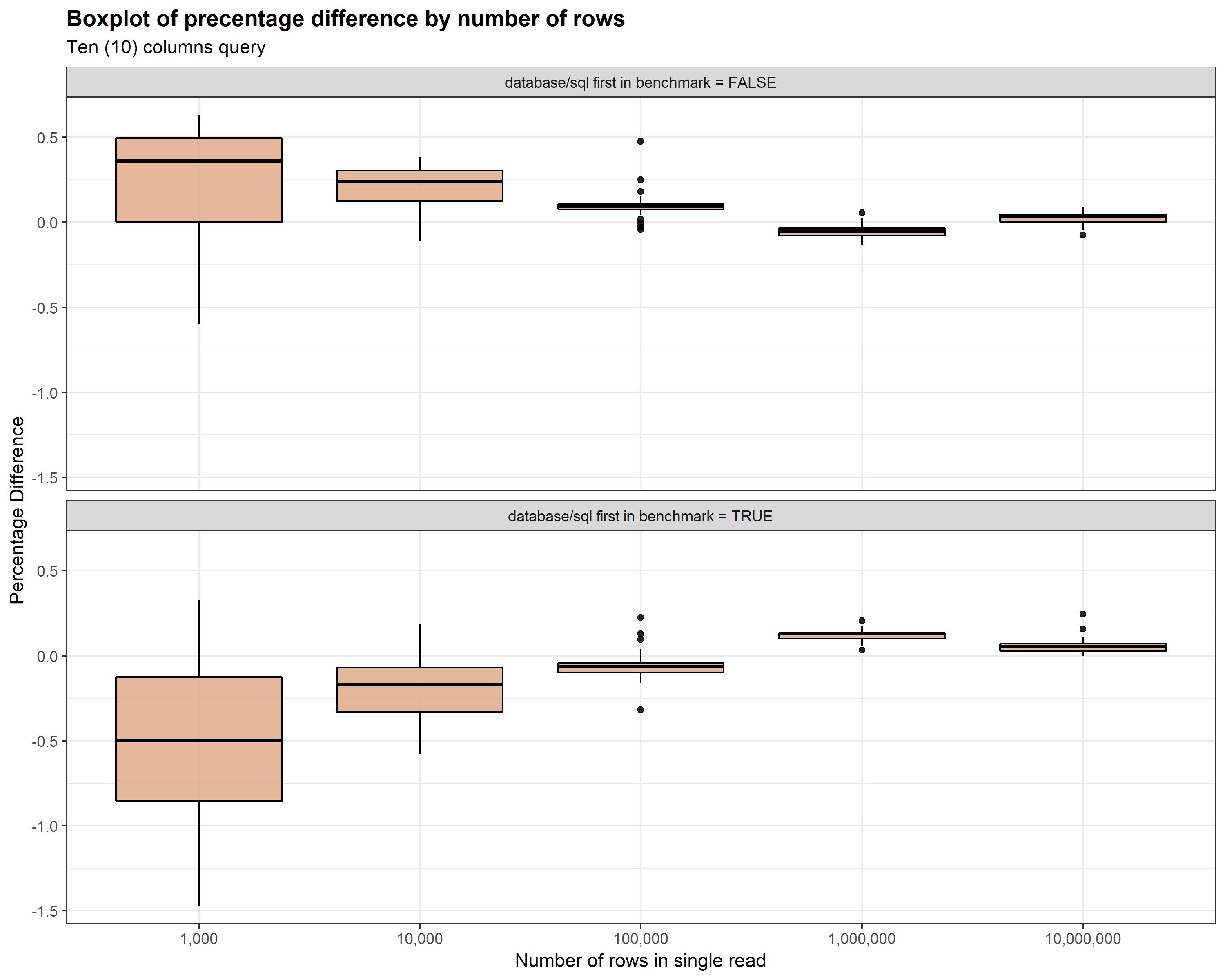
Figure 2: Boxplot of percentage difference in reading time by number of rows - case for ten columns Points.
Using standard go test -bench benchmark we can see that sqlx.Select also
does more number of allocations. For reading 10 000 of rows benchmark
statistics are displayed below:
go test -bench=. -benchtime=30s -benchmem
Result of go test bench command for 10k rows reading.
Summary
Based on benchmark results we can answer question about overhead - it's roughly
5% overhead of database reading using sqlx over standard database/sql package.
Performing the same benchmark in another environment might give slightly different
result but I think it shouldn't differ significantly and stays around 5%.
Appendix
- Link to benchmark source codes
- OS -
Microsoft Windows 10 Home 10.0 Build 18362 - Processor -
Intel Core i5-7200U, 2.50Ghz 2.71Ghz - Hard disk -
LITE-ON CB1-SD256 (SDD) - Database -
PostreSQL 10.10, compiled by Visual C++ build 1800, 64-bit - go version -
go1.13beta1 windows/amd64 - go database driver package -
github.com/lib/pq